ServicesService details
Statistical Modeling & ML for Research-Ready Outputs
I support research teams that need defensible analysis rather than one-off results. The workflow focuses on data QC, exploratory analysis, appropriate baselines, model diagnostics, and figures/tables that can survive peer review or technical reporting.
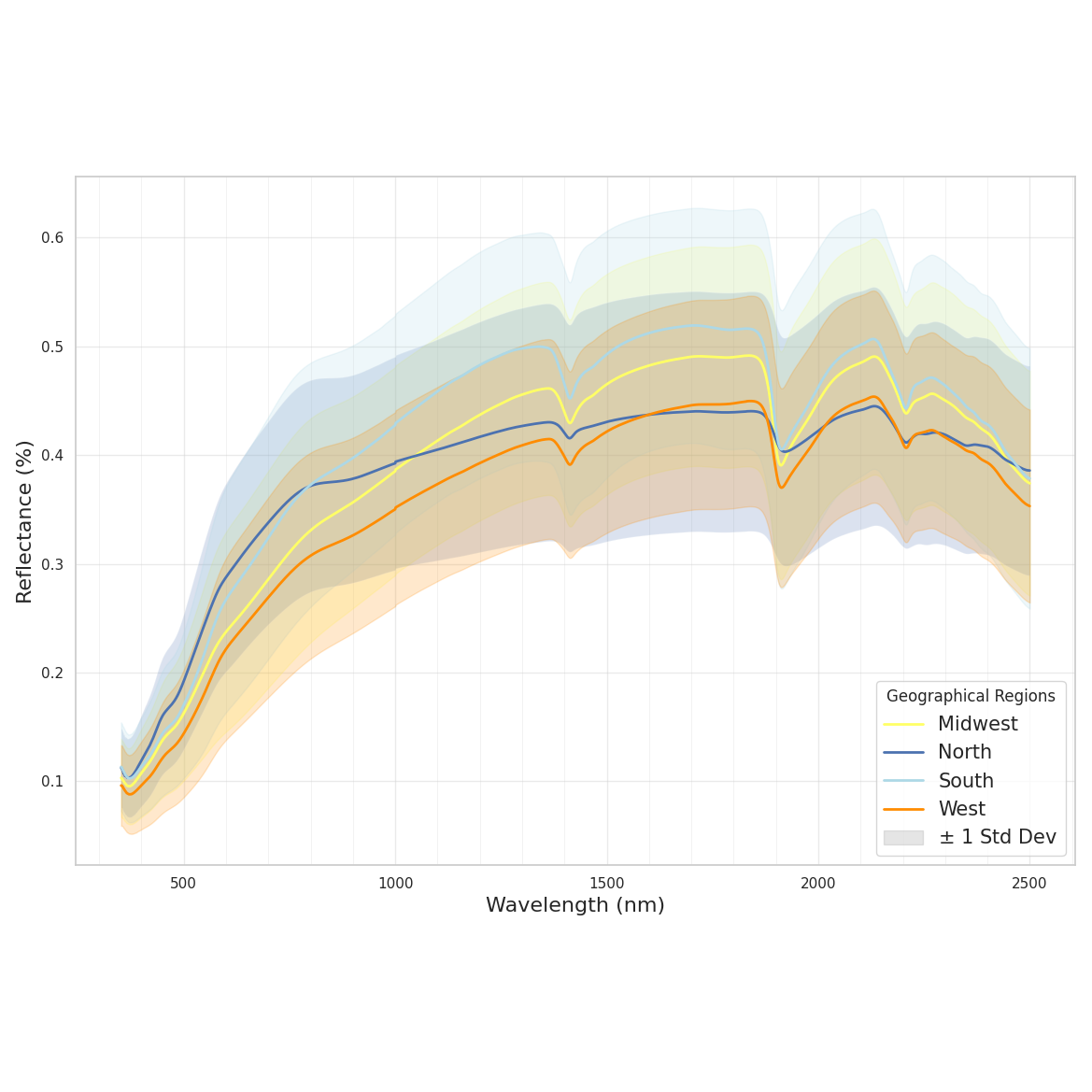
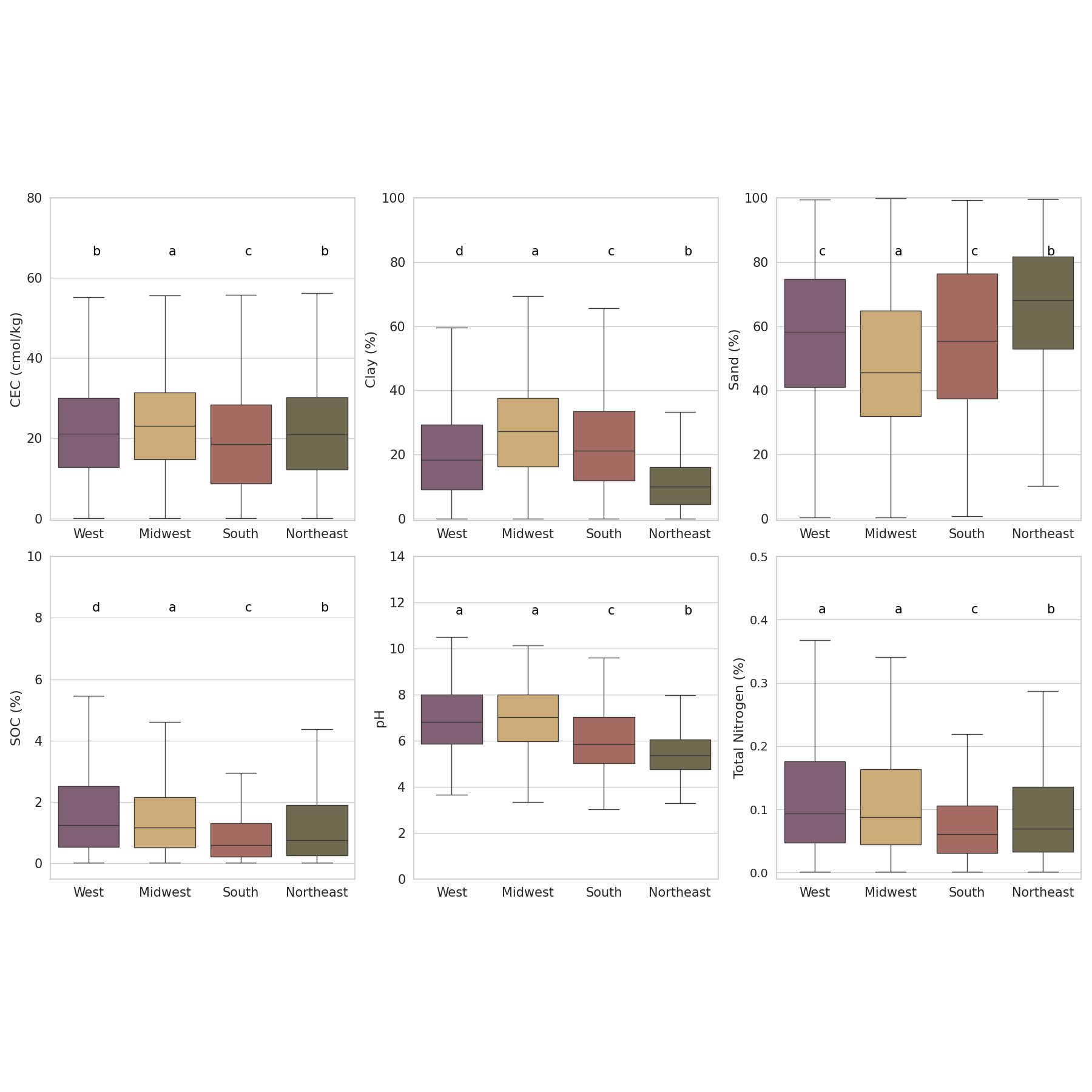
Overview
I support researchers with reproducible statistical analysis and machine learning that can stand up to technical review. The focus is data QC, appropriate baselines, transparent diagnostics, clear limitations, and outputs you can explain in a manuscript, report, or proposal.
Ideal collaborators
Graduate students, academic labs, NGOs, agencies, and applied teams working with soil, plant, water, spectroscopy, or environmental datasets who need credible analysis and clean figures without overstating results.
What you get
- QA/QC checks, tidy data tables, and documented variable definitions
- Exploratory analysis that identifies confounders, outliers, and data gaps early
- Benchmarking from simple baselines to ML and CNN models when appropriate
- Diagnostics and error analysis showing where models work, fail, and require caution
- Reviewer-ready figures, tables, and concise methods text you can adapt